Earlier this month, I posed some statistics interview questions. Here are possible answers.
1. Stirling’s formula holds that 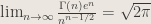
Answer: Suppose 
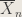

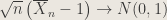
Therefore by the CLT,

for all 

We’ll omit the details.
2. Can you think of how regularization and prior distributions are connected?
Answer: Generally we can characterize the cost function as a log-likelihood. For instance, the sum-of-squares error in OLS given by

can be interpreted as a negative log-likelihood of

We can coerce a Bayesian treatment by thinking of the regression coefficients as random phenomena, so that

This prior belief about the regression coefficients can take the form of any regularization we may choose to include in the original formulation. For instance, suppose we really believe that the slope and intercept ought not be too big. An L2 regularization would mean
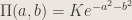
for some suitable constant 
3. Where might the CLT run aground?
Answer : Any number of obstacles to invoking the CLT exist, including non-finite variance, unstable variance, lack of independence, and so on. Specific examples include a ratio of two independent standard normal variables, ratios of exponentials, waiting times to exceed say the first measurement, and so on.
4. Can you offer a variance-stabilizing statistic for predicting success probability in a binomial sample? Provide a 
Answer : With the delta method, we can offer the test statistic

By the delta method, we have
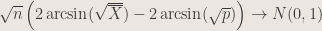
The confidence interval, with work, is
![\left[A-B,A+B\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5BA-B%2CA%2BB%5Cright%5D&bg=ebe7e0&fg=333333&s=0&c=20201002)
with
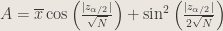
and

A candidate capable of deriving the aforementioned in an hour interview would achieve a near unconditional pass.
5. Where does maximum likelihood estimation run into trouble? Name three problems.
Answer : (1) Peakedness of the likelihood function can cause numerical instability, (2) sometimes the optimal solution falls outside the parameter space, and (3) there may be no global optimum.
A followup question is to query examples of each case. Simple ones are estimating the size of a binomial trial, estimating parameters in subtended distributions, and unidentifiable parameters, respectively. Answers may vary.
6. Consider a ratio of two exponential random variables. If your boss asked you to approximate its expectation, how would you answer it!
Answer : If you got number three above, you already know the answer : the expectation does not exist. Understanding the nuance is helpful in overcoming the challenges posed by ratio metrics.
7. If 

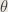
Answer : This is an excellent opportunity to discuss sufficiency, a satisfying means of describing information necessary to determining a parameter. It turns out that the maximum order statistic 


with
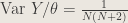
We can invoke Lehmann-Scheffe to claim our estimator is UMVUE, if we can show completeness, another convenient statistical property we’ll discuss more in the days ahead. Offering a confidence interval is an interesting follow-up.
Much of the above comes from insights in Statistical Inference by Casella and Berger. I’ll be interviewing Roger Berger in a few months for Algo-Stats. If you’ve made it this far in my article, please reach out to me to chat. npslagle
